Filter by categories

It’s not your UPS. It’s not your generator. So why is your data centre still going dark?
Uptime's 2026 outage analysis delivers a clear warning: after years of steady gains, reliability improvements are stalling. Power remains the leading cause of impactful outages, but the biggest emerging threats now sit outside the fence line - fibre cuts, grid constraints, and third‑party failures are all on the rise. Human error is a factor in the vast majority of incidents, and most outages could have been prevented with better processes. Costs keep climbing, with a growing share of outages now reaching seven figures. Meanwhile, confidence in public cloud resiliency is falling, and AI workloads are introducing new, poorly understood risks. If your resilience strategy still focuses only on internal systems, you're already behind.

Operations & Management Strategy: Keeping AI Facilities Reliable, Safe, and Efficient
Uptime Institute’s AI Infrastructure Advisory
Part 5: Operations & Management Strategy
A GPU can burn out in 30 seconds if coolant flow stops – that is the reality of operating an AI data center. Uptime Institute’s Part 5 covers staffing (experienced leaders are non‑negotiable), clear demarcation between IT and facilities for liquid cooling, safety in high‑current and medium‑voltage environments, shorter GPU lifecycles (three years vs. ten for CPUs), and the SOP/MOP/EOP documentation needed to run safely and reliably. Operations is not an afterthought - it is where value is made or lost.

Level 4 & 5 Commissioning: Testing AI Facilities for Real-World Workloads
Uptime Institute’s AI Infrastructure Advisory
Part 4: Level 4 & 5 Commissioning
Standard load banks are just heaters – they cannot simulate the volatile power draw and heat output of real GPU workloads. In Part 4, Uptime Institute explains why AI facilities require specialised load banks, DLC‑specific fluid cleanliness and pressure testing, continuous cooling validation, and third‑party witnessed Level 5 integrated system testing. Commissioning is not complete until your facility can survive sub‑second cooling failures.

Construction Oversight & Validation: Preventing Design‑to‑Build Drift in AI Facilities
Uptime Institute’s AI Infrastructure Advisory
Part 3: Construction Oversight & Validation
Fast AI builds are prone to design‑to‑build drift – small deviations that become costly remediation if caught late. Uptime Institute’s Part 3 details the physical demands of AI facilities: floor loading >2,000 kg per rack, multi‑story low‑latency designs, hybrid liquid/air cooling installation, and phased construction. Learn why independent milestone inspections are essential to protect your investment and schedule.

Technical Vendor Requirements & Evaluation: Selecting Cooling and Power Systems for AI
Uptime Institute’s AI Infrastructure Advisory
Part 2: Technical Vendor Requirements & Evaluation
Choosing the wrong cooling or power technology can lock you into obsolete infrastructure for years. In Part 2, Uptime Institute compares direct‑to‑chip (DLC) vs. immersion cooling, explains why GPU power fluctuations demand high‑di/dt UPS systems, and provides a structured vendor evaluation framework – including RFP templates, weighted criteria, and the importance of delivery penalties. Maintain owner control while benefiting from independent, vendor‑neutral guidance.

Design Development & Review: Technical Considerations for High-Density AI Facilities
Uptime Institute’s AI Infrastructure Advisory
Part 1: Design Development & Review
Conventional data centers run at 5–15 kW per rack; AI training clusters routinely hit 40–130 kW. According to Uptime Institute, this density forces a complete rethink of cooling, power, and physical space. Part 1 covers direct liquid cooling (DLC), continuous cooling requirements, two reference resiliency topologies (concurrently maintainable and fault tolerant), and the structural must‑haves – from 2,000+ kg racks to taller ceilings and expanded gray space.

From Design to Operations: A Complete Guide to AI Data Centre Infrastructure
Uptime Institute’s Guide to AI Data Center Infrastructure – A Five‑Stage Framework
AI data centers are not scaled‑up traditional facilities. Based on Uptime Institute’s five‑part advisory series, this condensed guide walks you through the entire infrastructure lifecycle: design, vendor selection, construction, commissioning, and operations. Learn why rack densities of 130 kW demand direct liquid cooling, why continuous cooling is non‑negotiable, and how to prevent design‑to‑build drift before it costs millions.
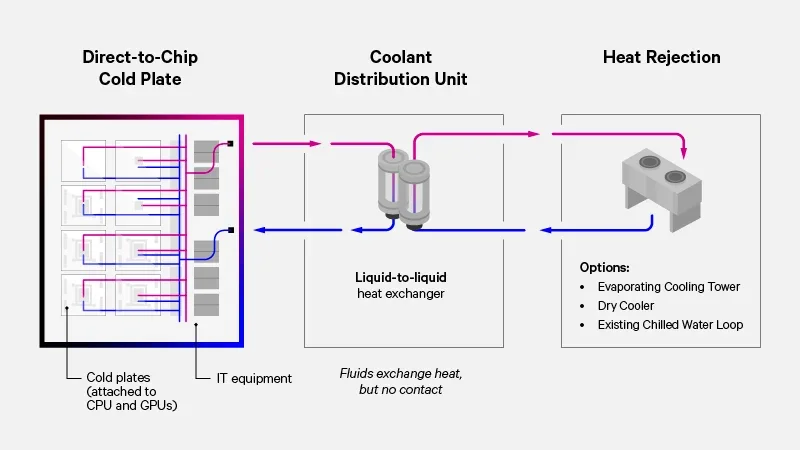
Beyond the Plumbing: Engineering Direct-to-Chip Cooling for AI Workloads
The Hidden Engineering Challenge of Direct‑to‑Chip Cooling
AI workloads don’t just run hotter – they run differently. Training a large language model can ramp GPU utilisation from 60% to 100% and back down within milliseconds, pushing coolant temperatures above 45°C in closed loops. That rapid thermal cycling demands response times measured in seconds, not minutes.
Direct‑to‑Chip (D2C) liquid cooling is the industry’s answer, but it introduces new risks: fluid inches from $40,000 GPUs, hundreds of potential leak points, and coolant chemistry that can corrode piping from the inside out.
And if a cooling anomaly strikes? You have roughly 5–10 seconds before the silicon throttles – or crashes a multi‑day training job.
Traditional data centre operations weren't built for this. Managing D2C requires fluid chemistry expertise, concurrent maintenance procedures for live liquid loops, and unified IT‑facilities alarm chains.
That’s the new engineering reality of AI infrastructure.

From Static Inventory to Lifecycle Intelligence
In a recent post, Uptime Institute highlighted that critical spares management is no longer a static decision - it's a moving target. Operators are shifting toward hybrid strategies that blend on-site stock with vendor agreements, but the real gap is lifecycle intelligence: knowing where each asset stands in its service life so spares, maintenance, and replacement plans evolve accordingly.

The Uptime Institute 2026 Vendor Survey: 3 Hard Truths About Data Centre Outages
The Uptime Institute's 2026 Vendor Survey reveals three hard truths: AI is mostly used for monitoring (54%) and predictive maintenance (44%) - not fixing problems. Cost savings (56%) and energy efficiency (55%) are the top metrics, not uptime. And human error (30%) and power failures (25%) still cause most outages.
Outage frequency may be declining, but the cost of each outage is rising - one in five now exceed $1 million.

Monitoring, power, and the rising compliance tide: 5 takeaways from the 2026 Uptime Resiliency Survey
What the 2026 data suggests: Uptime Institute’s latest resiliency survey finds that monitoring and analytics (53%) and electrical infrastructure upgrades (49%) remain the two most effective ways to improve data centre uptime - and the top areas for increased investment this year. Tellingly, the main justification for this spending is no longer ROI alone; operators are now citing design and operational standards as their lead argument. And 69% expect more resiliency regulations within three years.

Beyond Uptime: Engineering Resilience for the Long Haul
Apply the conditions that equipment will face in real-world scenarios for longevity and resilience to minimize weaknesses of products, services, and applications that can lead to premature failures.