Beyond the Plumbing: Engineering Direct-to-Chip Cooling for AI Workloads
The shift from traditional CPU-based servers to high-density GPU clusters has fundamentally broken the thermal model of the legacy data centre. This article picks up where our previous AI factory blog left off.
For decades, we relied on the law of large thermal mass - it took minutes for a server rack to heat up, giving Computer Room Air Conditioners (CRACs) plenty of time to react. But AI workloads, particularly training, have obliterated this safety buffer.
When you are running a large language model (LLM) training loop, a rack of GPUs can draw over 100kW. The thermal density is so extreme that temperatures change in seconds, not minutes.
This is why the industry is pivoting to Direct-to-Chip (D2C) liquid cooling. However, from an engineering and technical standpoint, D2C is not just a "plumbing upgrade." It is a fundamental re-architecture of how we think about risk, maintenance, and uptime.
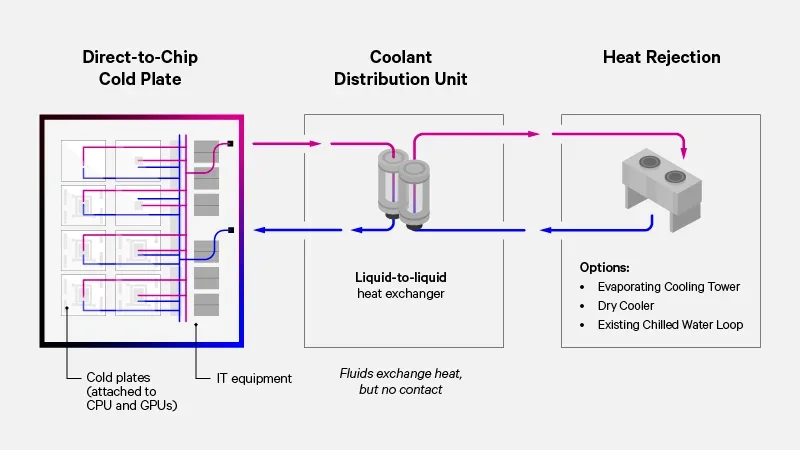
A diagram illustrating how direct-to-chip cooling works, where CDUs circulate liquid coolant to cold plates attached to server components. Source: Vertiv.
The Engineering Reality of Direct-to-Chip Cooling
Direct-to-Chip cooling involves circulating dielectric or deionized fluid through a cold plate mounted directly on the GPU or CPU. Heat is transferred from the silicon to the fluid, which then moves to a Coolant Distribution Unit (CDU) and ultimately to a facility water loop.
The technical benefits are undeniable (lower PUE, higher density). But the engineering challenges are significant:
Fluid Proximity: You are introducing water/fluid inches away from $40,000 GPUs.
Flash Evaporation: Unlike air, two-phase D2C systems rely on the latent heat of vaporization. If the flow stops, the fluid boils immediately, pressure spikes, and the rack shuts down in milliseconds.
Chemical Complexity: Coolant chemistry - pH drift, inhibitor depletion, and water contamination - directly affects heat transfer, corrosion rates, and system reliability.
Vendor Lock-In by Necessity: GPU vendors certify specific liquid cooling loop pressures, flow rates, and connector types. Go outside that spec, and you void your hardware warranty - or worse, watch a row of GPUs fry. Your cooling manifold supplier must match your GPU vendor’s internal manifold design.
1. Thermal Load Dynamics: Training vs. Inference
The single biggest misconception in AI cooling is assuming all AI workloads look the same. They don't. The thermal profile of AI training versus inference is dramatically different, and this variability is a key planning factor that some operators still underestimate.
AI Inference (e.g., chatbots, real-time search) tends to produce a constant, predictable load. Chips run at a high but stable utilization level, making heat dissipation reliable and control systems stable. From a control perspective, this is favorable - the thermal load remains steady, and cooling systems can be designed for constant parameters.
AI Training, however, is entirely different. Training algorithms can ramp from 60% utilization to 100% and drop back to a base load of 15 to 20% within a few milliseconds. Training runs GPUs at 90-100% capacity for weeks on end, pushing coolant temperatures to 45°C+ in closed-loop systems, creating mineral buildup and corrosion risks. These rapid spikes in thermal load demand extreme temperature fluctuations that require very fast response times - something conventional liquid cooling solutions, which lack adequate thermal reserves and part-load capability, are often unable to provide.
This distinction has profound engineering implications. For AI training, thermal reserves are now a critical factor. Cooling systems must be designed so they never reach their limits, even during massive load spikes. Standardized cooling concepts that aren't specifically designed for these dynamic load profiles are already hitting their physical limits.
2. Leak Mitigation: The Single Point of Failure
In a traditional air-cooled data centre, the risk of a cooling anomaly is an abstract heat issue. In a D2C environment, it is a physical catastrophe.
Every cold plate, every flexible tube, every quick-disconnect fitting is a potential failure point. Direct-to-chip cooling introduces dozens, sometimes hundreds, of new failure points compared to legacy systems.
The industry is rapidly developing solutions to mitigate these risks. Dedicated DTC liquid cooling services now provide customizable operational models, including detailed leak management protocols, safety procedures, and CDU management frameworks. But the engineering challenge remains acute:
Sensors: You need point-of-leak detection cables woven into every rack level.
Containment: Quick-disconnect fittings must be designed to prevent drips during maintenance. Mixing brands causes leaks or flow restriction.
Emergency Flow Control: Instant solenoid valve actuation upon pressure drop detection is mandatory.
Some vendors are pioneering leak-free, condensation-free two-phase D2C technologies that eliminate the risk of leaks entirely by using low-GWP (lower global warming potential) dielectric fluids in sealed loops. However, for most deployments, the focus is on safeguarding coolant health - real-time monitoring of coolant chemistry, glycol degradation, and contamination risks from commissioning through daily operation.
3. Fluid Management: The New Chemical Engineering Frontier
Cooling an AI cluster is no longer just a mechanical engineering problem - it's a chemical engineering problem.
In high-density AI environments, factors like pH drift, inhibitor depletion, and water contamination directly affect heat transfer, corrosion rates, and system reliability. A rise in coolant temperature increases corrosion rates, making thermal management and chemistry management inseparable. Untreated glycol solutions degrade over time to form organic acids that depress pH and accelerate corrosion, with uninhibited ethylene glycol being approximately 4.5 times more corrosive toward carbon steel than water.
Key monitoring protocols include:
pH: Target range pH 8.0-10.5 for glycol-based cooling systems.
Inhibitor Chemistry: Different inhibitors protect different metals.
Chloride Contamination: Chloride ions promote localized pitting corrosion, particularly in aluminum components, producing pinhole leaks that are difficult to detect.
Galvanic Corrosion: Mixed metals in the loop - copper vs. aluminium - cause a slow death for your GPU fleet. Every component must be compatibility-tested as a system.
Without rigorous fluid management, you are effectively "watching" your piping and cold plates dissolve from the inside out.
4. Hybrid Cooling: The Pragmatic Path Forward
Not every data centre can rip out its air-cooled infrastructure overnight. This is where hybrid cooling architectures come into play.
Hybrid cooling combines liquid cooling for the highest-density components (the GPUs themselves) with air-assisted cooling for the rest of the IT load (memory, network cards, SSDs). This approach has rapidly gained traction across the industry, with analysts forecasting that demand for direct liquid cooling solutions will more than double between 2025 and 2029, underscoring the critical role hybrid designs will play in driving wider industry adoption across both new builds and retrofits.
A leading player in this space is Vertiv, which has developed a comprehensive hybrid cooling portfolio designed for seamless integration. Vertiv's solution integrates liquid and air cooling technologies to meet the diverse needs of modern IT environments, supported by a centralised control platform that coordinates both systems for dynamic load balance and real-time monitoring. At the heart of their offering is the Vertiv CoolChip CDU 600, a liquid-to-liquid coolant distribution unit designed for in-row deployment that delivers up to 600 kW of scalable liquid cooling for high-density AI and HPC installations. For smaller deployments, Vertiv offers the Liebert XDU070, a liquid-to-air heat exchanger for direct-to-chip cooling applications that operates without facility chilled water — effectively plugging into an existing air-cooled environment to provide targeted liquid cooling without incurring the costs of major infrastructure changes. Designed to fit within raised-floor layouts, Vertiv's hybrid solutions can be deployed in both greenfield builds and retrofit installations, making them accessible to operators who are not ready to fully commit to a liquid-only future.
For colocation facilities and existing data centres, hybrid cooling offers a modular, incremental path to AI-readiness.
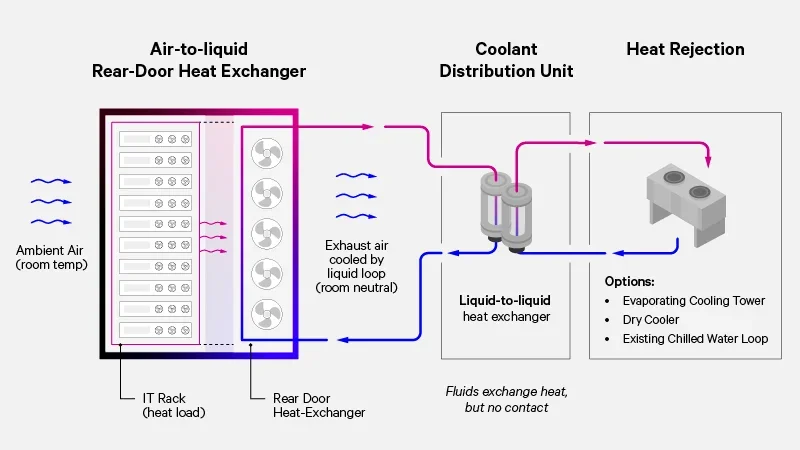
A diagram illustrating how rear door heat exchangers work, where CDUs connect hot and cold water to the heat exchanger. Source: Vertiv
Rethinking Uptime Tiers for AI (Training vs. Inference)
The Uptime Institute’s Tier Standard (Tier I to IV) has always been the gold standard for data centre reliability. However, applying these concepts to D2C cooling for AI requires a nuanced approach, especially when distinguishing between Training and Inference.
1. Concurrent Maintainability (The Tier III Challenge)
Concurrent Maintainability means you can take any component offline for maintenance without shutting down the IT load.
The D2C Problem: In a traditional air-cooled Tier III site, you can turn off a CRAC unit because the cold aisle still has air mixing. In a D2C system, if you need to replace a CDU pump or a distribution manifold, you are physically disconnecting the fluid loop. Air is a buffer; liquid is a direct conduit.
AI Inference Impact: Inference is real-time (think ChatGPT responses). Latency is king. Engineering Solution: For inference, you must design for N+1 redundancy on the CDU and implement blind-mate fluid connections at the rack level. This allows you to "hot swap" a cold plate loop without bleeding the entire rack.
2. Fault Tolerance (The Tier IV Challenge)
Fault Tolerance means no single failure causes an outage. This is where D2C gets controversial.
The Leak Scenario: A single failed O-ring on a GPU cold plate creates a drip. If that drip hits a live GPU bus bar, you have a fire or a short. Unlike a hot aisle containment issue (which just gets warm), a fluid leak is an immediate physical hazard.
AI Training Impact: Training is a long-duration, checkpoint-based workload. If a single GPU fails due to a thermal event, that node drops out. The orchestrator pauses the entire training job until the node returns. Result: A 2-second cooling fault can erase 3 days of training progress.
Engineering Solution: You need physical separation of fluid and power. This means:
Manifolds outside the rack (fluid never enters the IT chassis unless cold plated).
Leak detection cables woven into the server floor.
Emergency Flow Control that instantly isolates a rack via solenoid valves upon detection of a pressure drop.
The Operational Reality: "Seconds to Throttle"
A critical operational dynamic that engineers often miss is that a cooling anomaly can cascade to GPU throttling within moments.
In an air-cooled legacy world, a fan failure gives you 2-3 minutes of thermal coasting. In a D2C system for AI, you have roughly 5 to 10 seconds before the silicon hits its throttling temperature (usually 85°C).
This compresses your "response window" to nearly zero. You cannot rely on a human operator to fix this. You need:
PLC-based automation that bypasses central BMS (Building Management System) latency.
Flow meters on every branch that cross-reference GPU temperature telemetry.
How Uptime Institute Bridges the Gap
Traditional operations frameworks break down when faced with the interdependencies of AI infrastructure. The old model of siloed IT and facilities teams simply cannot manage the speed, density, and fluid dynamics of Direct‑to‑Chip cooling.
This is where the Uptime Institute’s AI Infrastructure Advisory: Operations and Management Strategy becomes critical.
Uptime recognises that managing D2C cooling requires a fundamentally different approach. Its advisory service helps engineering teams build purpose‑built programs that address three urgent priorities:
1. Staffing for Fluids
Your facilities team now needs expertise in fluid chemistry, pump curves, and leak remediation – skills that were irrelevant in traditional air‑cooled data centres. Uptime helps identify these gaps and develop targeted training.
2. Procedures for Concurrent Maintenance
Replacing a CDU pump or a distribution manifold in a live, high‑density AI cluster is no longer a routine task. Uptime helps develop runbooks that allow you to perform that maintenance without crashing an active training job – preserving days or weeks of model progress.
3. Integrating the Alarm Chains
Siloed alarms (IT vs. Facilities) create dangerous blind spots. Uptime guides you toward a unified System Health view, where a flow anomaly automatically triggers graceful GPU power capping rather than a hard crash that corrupts checkpoint data.
Through five focused service areas – Design Development and Review, Technical Vendor Requirements, Construction Oversight, Level 4 and 5 Commissioning, and Operations and Management Strategy – Uptime Institute helps organisations develop comprehensive operations plans. These plans cover qualifications, staffing levels, maintenance regimes, and continuous improvement, optimising the ongoing performance, reliability, and efficiency of AI infrastructure operations.
The Bottom Line
Implementing Direct-to-Chip cooling for AI is not just a mechanical engineering challenge; it is a risk management exercise. Whether you are running latency-sensitive inference (needing Tier III concurrent maintainability) or long-haul training (needing Tier IV fault tolerance), the old rules have changed.
You need a partner who understands how to write the policies, procedures, and training programs for this new reality. As Uptime Institute outlines in their advisory services, the goal is not just to keep the chips cool - it is to sustain performance, minimise downtime, and enable your team to manage AI infrastructure safely as the technology evolves.
For a deep dive into staffing plans, technology refresh impacts, and customised operations workshops, explore Uptime Institute’s AI Infrastructure Advisory services and connect with Ecanet Engineers to bring genuine AI infrastructure expertise to your project.